OWL 101
Introduction
It has long been realized that the Web could benefit by having content understandable and available in a machine processable form; and it is widely agreed that ontologies play a key role in providing the enabling infrastructure to support this goal.
Ontology is the study of the nature of existence, beings and their relations. In information science, ontology provides a means to create unambiguous knowledge. “An ontology” is a formal specification of the concepts, types, properties and interrelationships of entities within a domain of the real world.
Formal ontologies provide humans and machines an accurately understandable context or meaning. Ontologies ensure a common understanding of information. In practice, ontologies, describe and link disparate and complex data.
Ontologies enable reuse of foundational concepts in (upper) ontologies that are domain independent and can be used across domains.
Modularity of ontologies allows separation and recombination of different parts of an ontology depending on specific needs, instead of creating a single common ontology.
Extensibility of ontologies allows further growth of the ontology for the purpose of specific applications.
Maintainability of ontologies facilitates the process of identifying and correcting defects, accommodates new requirements, and copes with changes in an ontology.
Ontologies enable separation of design and implementation concerns, so they are flexible to changes in specific implementation technologies.
Informal ontologies may lead to ambiguities. Systems based on informal ontologies are more error-prone than systems based on formal ontologies. Formal ontologies allow automated reasoning and consistency checking (i.e. is my model logically sound?). Formal ontologies span from taxonomies of concepts related by subsumption relationships to complete representations of concepts related by complex relationships. Formal Ontologies include axioms to constrain their intended interpretation of the concepts.
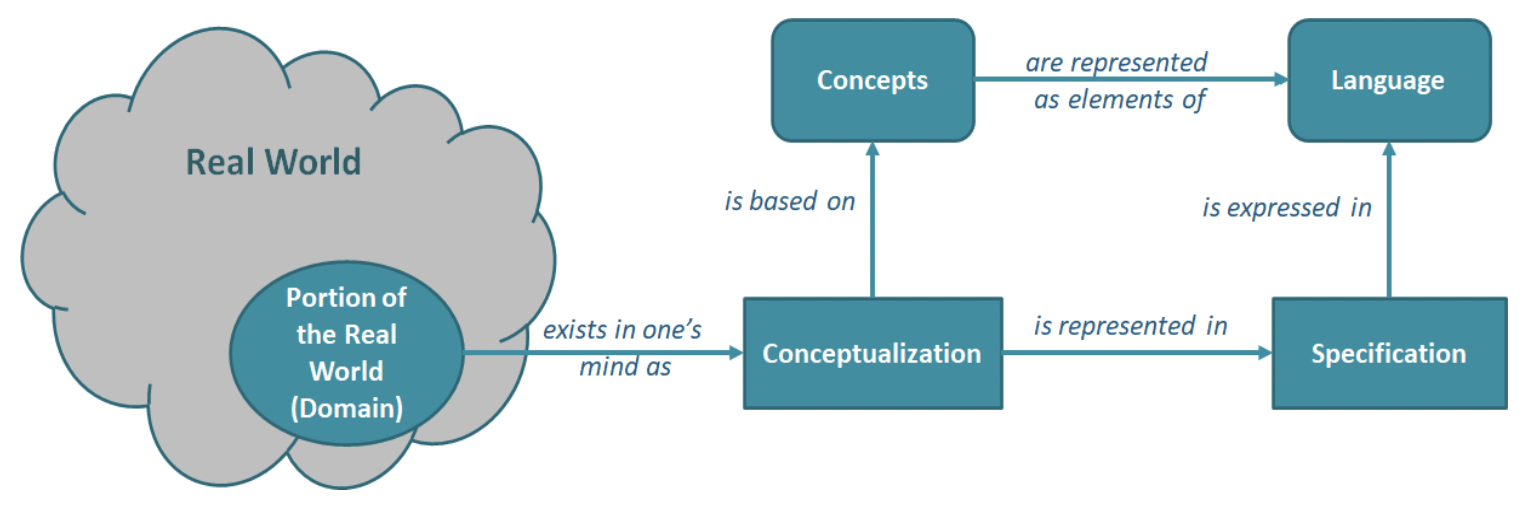 As depicted in the figure above, in practice, a developer or data modeler may want to model some portion of the real world. We might say, a conceptualization of some “domain” of interest may exist in one’s mind. The conceptualization is based on concepts, their properties and relationships to other concepts. But we need a language to express the concepts and relationships. In the end, we need a language to implement the specification (i.e., ontology).
As depicted in the figure above, in practice, a developer or data modeler may want to model some portion of the real world. We might say, a conceptualization of some “domain” of interest may exist in one’s mind. The conceptualization is based on concepts, their properties and relationships to other concepts. But we need a language to express the concepts and relationships. In the end, we need a language to implement the specification (i.e., ontology).
But how do we arrive at some (formal) ontology language?
In the 1990s there was a recognition that languages such as HTML and XML were insufficient for knowledge representation. HTML is oriented to rendering information in a human friendly presentation. XML provides a platform-independent data exchange model.
In 1999, the European Union sponsored development of the Ontology Inference Layer (OIL). OIL was based on strong formal foundations of Description Logics, namely SHIQ. OIL was compatible with a RDFS, which was already standardized in 1998.
In 2000, the Defense Advanced Research Projects Agency (DARPA) initiated the DARPA Agent Markup Language (DAML) project. DAML was to serve as the foundation for the next generation of the Web which would increasingly utilize “smart” agents and programs. One goal was to reduce the heavy reliance on human interpretation of data. DAML extended XML, RDF and RDFS to support machine understandability. DAML included “some” strong formal foundations of Description Logics, but focused more on pragmatic application.
Circa 2001, groups from the US and the EU collaborated to merge DAML and OIL which was known as DAML+OIL. DAML+OIL provided formal semantics that support machine and human understandability. This new language also provided axiomatization, or inference rules to expand reasoning services, that provided machine operationalization.
In 2004, the World Wide Web Consortium (W3C) derived the Web Ontology Language (OWL) from DAML+OIL and published it as a “standard” knowledge representation language for authoring ontologies. The initial OWL specification featured three “species” OWL: OWL Lite, OWL DL, and OWL Full, each providing increasing expressiveness and sophistication.
In 2009, the W3C released OWL 2 which articulated different versions of OWL tailored to different reasoning requirements and application areas. The latest W3C OWL 2 recommendation is dated 11 December 2012.
OWL is now the ontology (think “schema”) language of the Semantic Web. It is one of the core Semantic Web standards you must be familiar with, along with RDF and SPARQL.
OWL’s two primary uses are:
- Expressive and flexible data modeling
- Efficient automated reasoning
This lesson provides a high level introduction to OWL and is suitable for beginners. A more detailed nuts & bolts lesson on creating your first ontology will come next.
Objectives
After completing this lesson, you will know:
- The four main kinds of modern computing languages, and which kind OWL is
- Three advantages of OWL over other languages of its kind
- A few of the tools available for creating ontologies using OWL
Prerequisites
Today’s Lesson
Four main types of computer languages are in use today.
- Imperative languages, such as C/C++, Java, Javascript, Lisp, and Perl. These languages are designed to let you easily provide a sequence of instructions that tell the computer how to do something. For example, these languages might be used to tell a computer how to compute the 100th digit of PI, how to draw a monster on the screen, or how to process an online book order.
- Query languages, such as SQL and XQuery. These languages assume the existence of a database of some sort and are simply used to ask for a specific piece of information.
- Data languages, such as XML, HTML, and JSON. These languages don’t do anything, and they don’t ask for anything. They are simply a standard format for conveying data from one machine or person to another.
- Modeling languages, such as XSD, UML, and (in a way) SQL. These languages don’t necessarily do anything or ask for anything, and they don’t really convey any actual data. Rather, they say something about data.
OWL falls into the last category—it is a modeling language.
Although OWL is a modeling language in the classical sense, it has many advantages compared to the modeling languages that came before it.
Advantage 1: OWL is Expressive
Legacy languages such as XSD, UML, and SQL are adequate for listing a number of classes and properties and building up some simple hierarchical relationships. For example, SQL allows you to build a new table for each class, add a new column for each property, and specify some basic relationships using foreign keys.
However, SQL does not easily allow you to represent subclass relationships (e.g., “all Electronic Book Orders are a kind of Financial Transaction”).
More expressive languages such as UML make static subclasses easy, but even they cannot easily represent dynamic relationships (e.g., “All Financial Transactions of Less than $1000 are Tax Free Transactions”).
One of the distinguishing features of OWL is that it can be used to express extremely complicated and subtle ideas about your data. OWL specifies concepts, relationships, as well as characteristics of concepts and relationships in a human and machine understandable model.
OWL goes beyond simple syntactic standards; it is based on sound mathematical logic. Since most organizations don’t have staff logicians, this might seem like a rather obscure, academic feature; but with OWL it is possible to know exactly what a set of data means (in a mathematical sense), and hence to know when some data provided in response to a request actually satisfies the request. In other words, OWL is expressive and unambiguous.
Advantage 2: OWL is Flexible
Currently, most of the technologies that employ data modeling languages are designed using a rigid “Know the questions. Build the Model. Use the Model” mindset. In other words, they are “use case driven.” One builds a model based on known user questions.
As an example, suppose you want to change a property (i.e., column) in a relational database. You had previously thought that the property was single-valued, but now it needs to be multi-valued. For almost all modern relational databases, this change would require you to delete the entire column for that property and then create an entirely new table that holds all of those property values, plus a foreign key reference.
This is not only a lot of work, but it will also invalidate any indices that deal with the original table. It will also invalidate any related queries (i.e., use cases) that your users have written. In short, making that one change can be very difficult and complicated. Often, such changes are so troublesome that they are simply never made.
Another common challenge is “semantic drift.” Over time, our understanding of the model may change. We need to update the model to reflect our new understanding. But this is so infeasible in traditional models that developers and users load new or different data in existing schema properties. For example, a column that was intended to hold data about “street names” might end up containing an entire address; thus “freeing up” other columns for new uses. As you can imagine, this leads to additional problems.
By contrast, all data modeling statements (along with everything else) in OWL are RDF triples and are, therefore, incremental, by their very nature. Enhancing or modifying a data model after the fact can be easily accomplished by modifying the relevant triple. Most OWL-based technologies take advantage of OWL’s flexibility by supporting such straightforward changes.
Another way of saying this is that OWL is based on an “open world assumption,” which in short means that it expects change.
Advantage 3: OWL is Efficient
OWL allows you to use your data model to support many different kinds of reasoning tasks. By “reasoning,” we mean machine reasoning that makes implicit data explicit. For example, if your OWL model specifies a class called “Mammal,” and your model says “a Dolphin is a kind of Mammal” and the knowledge graph contains the statement “Flipper is a Dolphin,” then the reasoner infers that “Flipper is a Mammal” and creates this as a new fact in the knowledge graph.
This powerful ability to support reasoning on data and metadata allows increased sophistication in information retrieval applications and actually reduces the complexity of queries needed to retrieve data. Additionally, and perhaps most importantly, OWL is a critical enabler to machine-to-machine autonomy (e.g. ML/AI).
OWL defines built-in “profiles” that allow you to employ different kinds of reasoning based on your individual goals.
Importantly, on today’s data processing designs, such as Massively Parallel Processing (MPP), machine reasoning can be performed more efficiently on large knowledge graphs.
OWL Tools
Many software packages are now available for creating ontologies using OWL.
- Stanford University’s Protégé, a free, open-source ontology editor
- TopBraid Composer from TopQuadrant
- Any text editor you have lying around
Unlike some other languages, which always look the same, OWL actually can be “written down” in many different ways. OWL—as with all RDF—can be expressed in a canonical OWL/XML format as well as RDF/XML format. It can also be expressed in more human readable formats such as TRIG, Manchester, Turtle, and Functional-Style.
Worth noting, OWL is a graph structure, not a tree structure like XML. Just because OWL can be serialized in an XML syntax, do not think of OWL as “yet another XML language.” OWL is about knowledge representation, meaning. XML is a data/metadata conveyance, or container. XML Schema (XSD) is a way to specify a valid structure, a contract.
Details on the OWL syntax standards, as well as some examples of how to switch dynamically between various syntaxes can be found on the W3C website.
Conclusion
OWL’s expressiveness, flexibility, and efficiency make it an ideal modeling language for creating Web ontologies that represent exceptionally complex and refined ideas about data. In the next lesson, RDFS vs. OWL we’ll compare RDFS and OWL and discuss when you should use one vs. the other.



